
So I don't have too many interesting images tonight, just lots of render statistics. But this is totally sweet cause it looks like it made a big difference.
The really cool thing though is tonight I tried running a compiler optimization flag, changing from a debug build to an optimized build. Well folks, the Venus De Milo model that was rendering in 46 minutes on my Laptop at home is now rendering in... 10 seconds!!! This is a 276 TIMES speedup... probably my most awesome speedup of all the Raytracing tests I have been doing. Sweet.
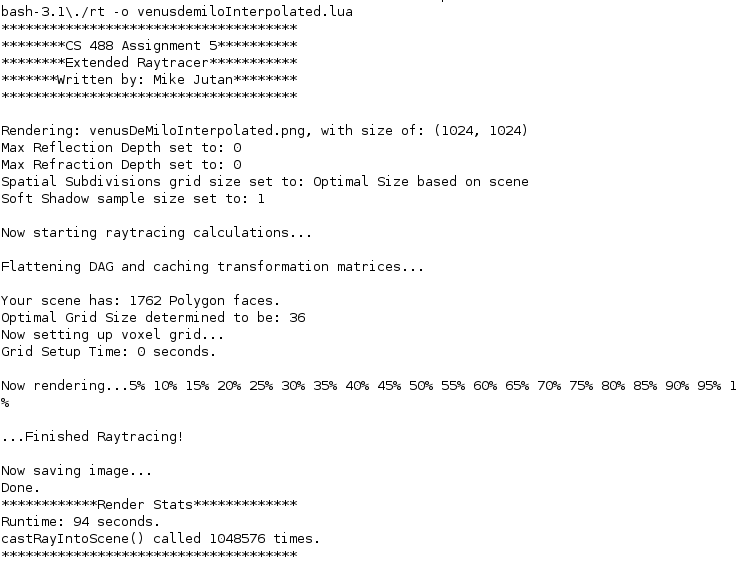
Venus De Milo runtime with 1 Process (94 seconds)
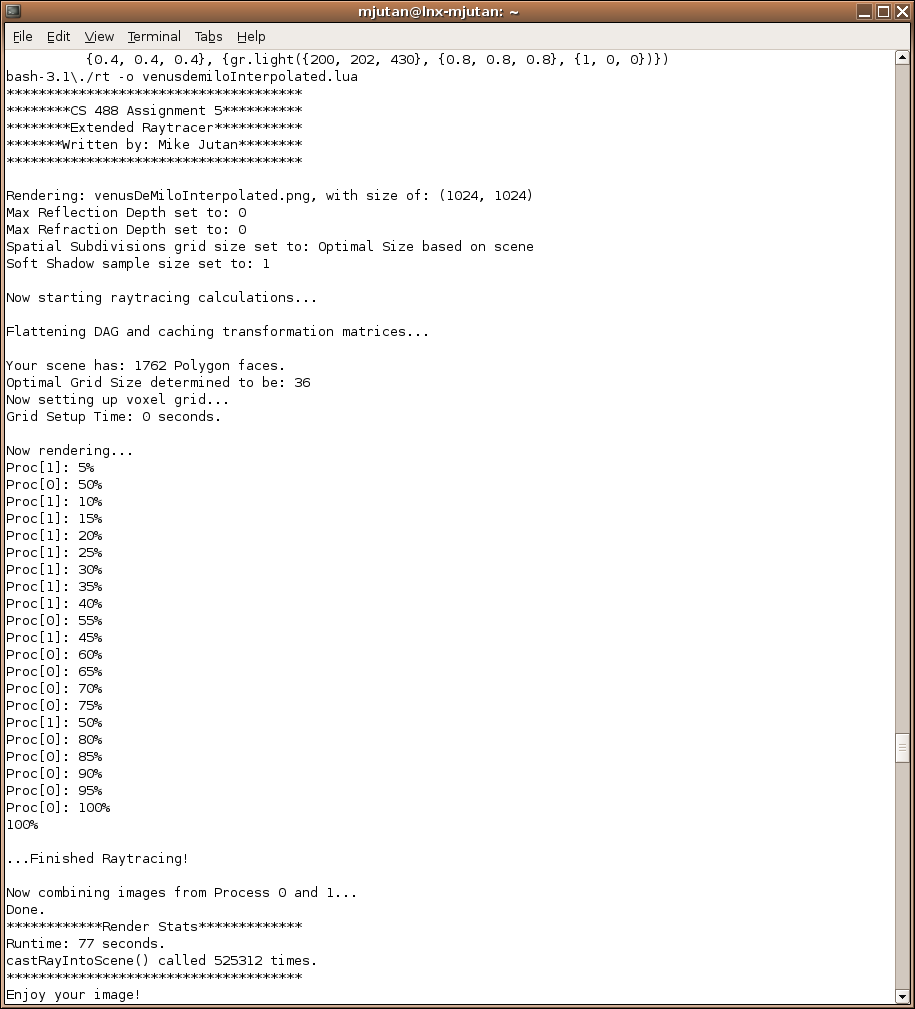
Venus De Milo runtime with 2 Processes (optimal - 77 seconds)

Venus De Milo runtime with 4 Processes (note this is slower than just 1 Process - 145 seconds)

Two processes from above (77 seconds), now runs in 22 seconds with an Optimized build
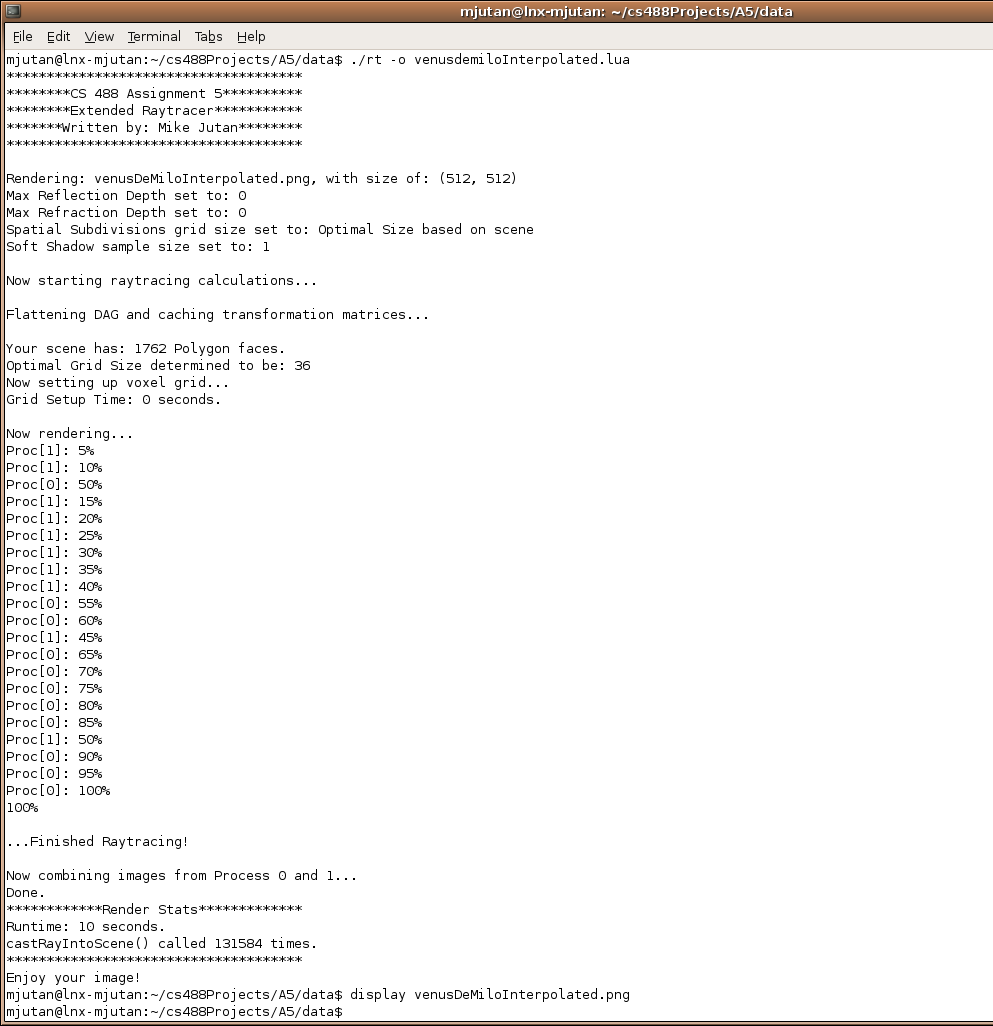
Venus De Milo on my Laptop with an Optimized build, was 46 minutes at start, now 10 seconds!

Table image rendered with 2 processes and optimized build

2 procs without optimization (~17.5 minutes)

2 procs with optimized build (~4 minutes)
No comments:
Post a Comment